This blog is an open source code analysis of the paper by Fei-Fei Li et al
数据处理部分 models.py 在第一篇代码解析的基础上,本文主要是有关网络模型models.py的介绍
关于torch.nn.Module,这里引用一下其他博主的介绍https://blog.csdn.net/lovebasamessi/article/details/103222278
在pytorch中,nn.Module是所有神经网络单元的基类。pytorch在nn.Module中实现了__call__方法,而在__call__方法中调用了forward函数。__call__方法的主要作用是是类对象具有类似函数的功能,可以在类对象中进行传参,而__call__方法中又调用了forward函数。pytorch中的nn.Module类都包含了__init__方法与__call__方法。
__init__:类的初始化函数,类似C++中的构造函数
__call__:使得类对象具有类似函数的功能
举个例子,假设A是一个class,a是A的一个类对象,当我们执行a=A(),这会调用__init__方法构造类的对象;而当我们执行a(),其会调用__call__方法,而在__call__方法内部又会调用forward函数,注意,这是通过类对象调用的,所以说使得类对象具有类似函数的功能。
make_mlp() make_mlp主要功能是构造多层的全连接网络,并且根据需求决定激活函数的类型,其参数dim_list是全连接网络各层维度的列表.get_noise函数主要是生成特定的噪声。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # 构造多层的全连接网络 # 根据需求决定激活函数的类型 # dim_list是全连接网络各层维度的列表 def make_mlp(dim_list, activation='relu', batch_norm=True, dropout=0): layers = [] for dim_in, dim_out in zip(dim_list[:-1], dim_list[1:]): layers.append(nn.Linear(dim_in, dim_out)) if batch_norm: layers.append(nn.BatchNorm1d(dim_out)) if activation == 'relu': # 是否需要加relu layers.append(nn.ReLU()) elif activation == 'leakyrelu': # 是否需要加leakyrelu layers.append(nn.LeakyReLU()) if dropout > 0: # 加入nn.Dropout层,元素置零的概率为p layers.append(nn.Dropout(p=dropout)) return nn.Sequential(*layers)
关于nn.Sequential(layers)非关键字参数的用法https://blog.csdn.net/weixin_43560675/article/details/108905632?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~aggregatepage~first_rank_ecpm_v1~rank_v31_ecpm-1-108905632.pc_agg_new_rank&utm_term=nn.Sequential%28 layers%29+return&spm=1000.2123.3001.4430
get_noise() 然后是根据shape大小生成特定噪声
1 2 3 4 5 6 7 8 9 10 # 生成特定的噪声 def get_noise(shape, noise_type): if noise_type == 'gaussian': # 高斯分布 # return torch.randn(*shape).cuda() return torch.randn(*shape).to(device) elif noise_type == 'uniform': # 均匀分布 # return torch.rand(*shape).sub_(0.5).mul_(2.0).cuda() return torch.rand(*shape).sub_(0.5).mul_(2.0).to(device) # sub_(0.5).mul_(2.0)减0.5在乘上2,生成[-1,1]的均匀分布 raise ValueError('Unrecognized noise type "%s"' % noise_type)
Encoder(nn.Module) 在介绍Encoder部分之前,可能需要先明确Dataloader一次送入网络的数据格式
obs_traj: 观察到(已知)的序列,N(Batch_size)个sequence堆叠在一起并按帧的先后排列 [obs_len, $\sum_{i=1}^N n_i$, 2]
输入的轨迹序列会被扩充到embedding_dim维,LSTM输入的特征向量也是embedding_dim维,隐藏向量的维数h_dim,https://blog.csdn.net/tangweirensheng/article/details/120725172
Inputs: input, (h_0, c_0)
以训练句子为例子,假如每个词是100维的向量,每个句子含有24个单词,一次训练10个句子。那么batch_size=10,seq=24,input_size=100。(seq指的是句子的长度,input_size作为一个x_{t}的输入) ,所以在设置LSTM网络的过程中input_size=100。由于seq的长度是24,那么这个LSTM结构会循环24次最后输出预设的结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Encoder(nn.Module): """Encoder is part of both TrajectoryGenerator and TrajectoryDiscriminator""" def __init__( self, embedding_dim=64, h_dim=64, mlp_dim=1024, num_layers=1, dropout=0.0 # 不用dropout ): super(Encoder, self).__init__() self.mlp_dim = 1024 # 没有使用? self.h_dim = h_dim # LSTM中隐层的维度 self.embedding_dim = embedding_dim # 词向量维数(数据的特征维数) self.num_layers = num_layers # 堆叠LSTM的层数 self.encoder = nn.LSTM( embedding_dim, h_dim, num_layers, dropout=dropout ) self.spatial_embedding = nn.Linear(2, embedding_dim) # 全连接层
同时,在还定义了一个全连接层
1 2 3 obs_traj_embedding = self.spatial_embedding(obs_traj.contiguous().view(-1, 2)) obs_traj_embedding = obs_traj_embedding.view( -1, batch, self.embedding_dim)
将[***len, $\sum {i=1}^N n_i$, 2]大小变成[obs_len, $\sum_{i=1}^N n_i$, 64]
在LSTM网络中,隐藏层的初始状态$h_0,c_0$设置为全0
1 2 3 4 5 6 7 8 9 def init_hidden(self, batch): return ( # GPU # torch.zeros(self.num_layers, batch, self.h_dim).cuda(), # torch.zeros(self.num_layers, batch, self.h_dim).cuda() # CPU torch.zeros(self.num_layers, batch, self.h_dim).to(device), torch.zeros(self.num_layers, batch, self.h_dim).to(device) )
在class Encoder(nn.Module)里,还有一个就是forward()函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def forward(self, obs_traj): """ Inputs: - obs_traj: Tensor of shape (obs_len, batch, 2) Output: - final_h: Tensor of shape (self.num_layers, batch, self.h_dim) """ # Encode observed Trajectory batch = obs_traj.size(1) # obs_traj_embedding = self.spatial_embedding(obs_traj.view(-1, 2)) obs_traj_embedding = self.spatial_embedding(obs_traj.contiguous().view(-1, 2)) # view(-1, 2)把数据变成两列 obs_traj_embedding = obs_traj_embedding.view( -1, batch, self.embedding_dim) state_tuple = self.init_hidden(batch) output, state = self.encoder(obs_traj_embedding, state_tuple) # 隐藏状态h_t记为final_h, state = h_t,c_t final_h = state[0] return final_h
总的来说,Encoder的作用就是就是把一个batch的数据[obs_len, $\sum_{i=1}^N n_i$, 2]编码成对应的$h_f$[num_layer, $\sum_{i=1}^N n_i$, 64]
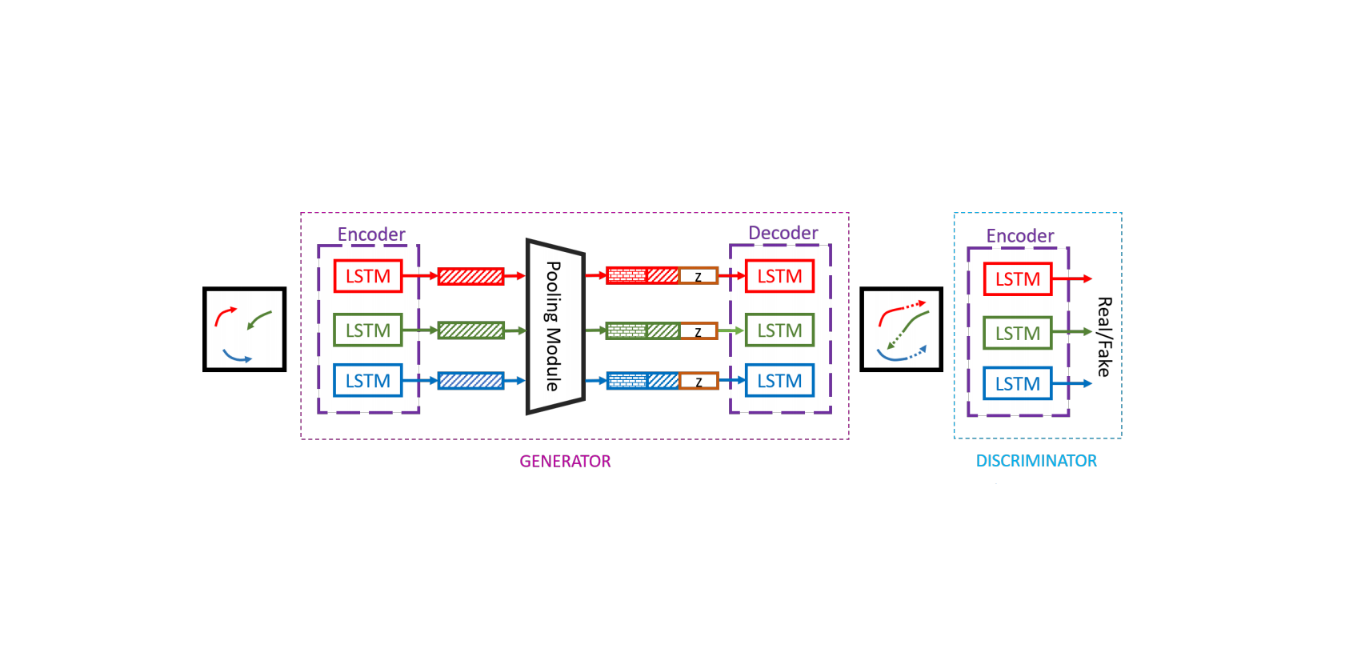
为了便于理解,这里引用了大佬制作的图片
“另外,源代码中有一个地方与论文中描述的不太一样,论文中在2*16的全连接层之后接了Relu激活函数,但是在源代码中并没有体现。”
PoolHiddenNet(nn.Module) 在分析class Decoder()之前先来看池化层class PoolHiddenNet
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def __init__( self, embedding_dim=64, h_dim=64, mlp_dim=1024, bottleneck_dim=1024, activation='relu', batch_norm=True, dropout=0.0 ): super(PoolHiddenNet, self).__init__() self.mlp_dim = 1024 self.h_dim = h_dim self.bottleneck_dim = bottleneck_dim self.embedding_dim = embedding_dim mlp_pre_dim = embedding_dim + h_dim mlp_pre_pool_dims = [mlp_pre_dim, 512, bottleneck_dim] # 全连接层 self.spatial_embedding = nn.Linear(2, embedding_dim) # MLP,调用定义的make_mlp()构造nn.linear() self.mlp_pre_pool = make_mlp( mlp_pre_pool_dims, activation=activation, batch_norm=batch_norm, dropout=dropout)
在PoolHiddenNet类中,作者还定义了一个repeat()函数,用于复制序列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def repeat(self, tensor, num_reps): """ Inputs: -tensor: 2D tensor of any shape -num_reps: Number of times to repeat each row Outpus: -repeat_tensor: Repeat each row such that: R1, R1, R2, R2 """ col_len = tensor.size(1) # 返回张量的行数 tensor = tensor.unsqueeze(dim=1).repeat(1, num_reps, 1) # unsqueeze(dim)在dim位置增加一维 (2)->unsqueeze(dim=1)->(2,1) # repeat(a, b, c) 复制a个,b行,c个原向量 tensor = tensor.view(-1, col_len) # 变成col_len列数据 return tensor
forward()函数的第一个参数h_states就是Encoder的输出final_h,其维度为[num_layers, batch, hidden_size],在程序中即[1, batch, 32],batch即batch_size个sequence序列中的总人数$\sum_{i=1}^N n_i$,每一批数据其个数一般是不相等的。
1 2 3 seq_start_end = [[start, end] for start, end in zip(cum_start_idx, cum_start_idx[1:])] # seq_start_end = [[0, 2], [2, 5], [5, 7], [7, 11]...]
seq_start_end是一个batch数据中,每个sequence包含的有效轨迹的起始序号
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 def forward(self, h_states, seq_start_end, end_pos): """ Inputs: - h_states: Tensor of shape (num_layers, batch, h_dim) - seq_start_end: A list of tuples which delimit sequences within batch - end_pos: Tensor of shape (batch, 2) Output: - pool_h: Tensor of shape (batch, bottleneck_dim) """ pool_h = [] # 按照每个sequcence循环 for _, (start, end) in enumerate(seq_start_end): start = start.item() end = end.item() num_ped = end - start # 抽取第i个sequcence中的轨迹对应的h_f curr_hidden = h_states.view(-1, self.h_dim)[start:end] curr_end_pos = end_pos[start:end] # Repeat -> H1, H2, H3, H1, H2, H3, H1, H2, H3 curr_hidden_1 = curr_hidden.repeat(num_ped, 1) # Repeat position -> P1, P2, P3, P1, P2, P3, P1, P2, P3 curr_end_pos_1 = curr_end_pos.repeat(num_ped, 1) # Repeat position -> P1, P1, P1, P2, P2, P2, P3, P3, P3 curr_end_pos_2 = self.repeat(curr_end_pos, num_ped) curr_rel_pos = curr_end_pos_1 - curr_end_pos_2 # 将[batch*batch,2]数据输入至2*64的全连接层得到[batch*batch,64]的curr_rel_embedding curr_rel_embedding = self.spatial_embedding(curr_rel_pos) # 对curr_rel_embedding, curr_hidden_1做拼接 mlp_h_input = torch.cat([curr_rel_embedding, curr_hidden_1], dim=1) # 将拼接的数据送入由二个全连接层构造的MLP, 得到[N*N, 1024] curr_pool_h = self.mlp_pre_pool(mlp_h_input) # 做maxpool操作 curr_pool_h = curr_pool_h.view(num_ped, num_ped, -1).max(1)[0] # 对这批数据所有序列都进行相应的处理,新的pool_h为[batch,8],每一行对应一个人 pool_h.append(curr_pool_h) pool_h = torch.cat(pool_h, dim=0) return pool_h
forward函数内部对DataLoader加载的batch_size个sequence序列逐次处理。在对每一个序列进行处理时,对每一个序列处理的示意图如下图所示。
Decoder(nn.Module) 然后就是class Decoder()部分,它的__init__方法中定义了一个LSTM网络结构,一个2*16的全连接层,一个32*2的全连接层,并且根据是否每生成一次预测数据都池化一次又定义了池化层与全连接层。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Decoder(nn.Module): """Decoder is part of TrajectoryGenerator""" def __init__( self, seq_len, embedding_dim=64, h_dim=128, mlp_dim=1024, num_layers=1, pool_every_timestep=True, dropout=0.0, bottleneck_dim=1024, activation='relu', batch_norm=True, pooling_type='pool_net', neighborhood_size=2.0, grid_size=8 ): super(Decoder, self).__init__() self.seq_len = seq_len self.mlp_dim = mlp_dim self.h_dim = h_dim self.embedding_dim = embedding_dim self.pool_every_timestep = pool_every_timestep self.decoder = nn.LSTM( embedding_dim, h_dim, num_layers, dropout=dropout )
其中有几个参数
pool_every_timestep = True # 每一次预测后是否根据新的坐标重新池化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 if pool_every_timestep: if pooling_type == 'pool_net': self.pool_net = PoolHiddenNet( embedding_dim=self.embedding_dim, h_dim=self.h_dim, mlp_dim=mlp_dim, bottleneck_dim=bottleneck_dim, activation=activation, batch_norm=batch_norm, dropout=dropout ) # elif pooling_type == 'spool': # ... mlp_dims = [h_dim + bottleneck_dim, mlp_dim, h_dim] self.mlp = make_mlp( mlp_dims, activation=activation, batch_norm=batch_norm, dropout=dropout ) self.spatial_embedding = nn.Linear(2, embedding_dim) self.hidden2pos = nn.Linear(h_dim, 2)
mlp在Decoder中主要用在pool_h和final_encoder_h拼接之后,然后输出h_dim(64)维的向量,所以其输入维度是h_dim(64)和bottleneck_dim(64)之和即128维。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 def forward(self, last_pos, last_pos_rel, state_tuple, seq_start_end): """ Inputs: - last_pos: Tensor of shape (batch, 2) - last_pos_rel: Tensor of shape (batch, 2) - state_tuple: (hh, ch) each tensor of shape (num_layers, batch, h_dim) - seq_start_end: A list of tuples which delimit sequences within batch Output: - pred_traj: tensor of shape (self.seq_len, batch, 2) """ batch = last_pos.size(0) pred_traj_fake_rel = [] decoder_input = self.spatial_embedding(last_pos_rel) decoder_input = decoder_input.view(1, batch, self.embedding_dim) for _ in range(self.seq_len): # seq_len = obs_len + pred_len # 为什么是seq_len而不是pred_len output, state_tuple = self.decoder(decoder_input, state_tuple) # decoder生成的相对上一帧的坐标(预测值) rel_pos = self.hidden2pos(output.view(-1, self.h_dim)) curr_pos = rel_pos + last_pos # 得到绝对坐标 if self.pool_every_timestep: # 预测出一帧的坐标变化后是否要重新池化 decoder_h = state_tuple[0] pool_h = self.pool_net(decoder_h, seq_start_end, curr_pos) decoder_h = torch.cat( [decoder_h.view(-1, self.h_dim), pool_h], dim=1) decoder_h = self.mlp(decoder_h) decoder_h = torch.unsqueeze(decoder_h, 0) state_tuple = (decoder_h, state_tuple[1]) embedding_input = rel_pos decoder_input = self.spatial_embedding(embedding_input) decoder_input = decoder_input.view(1, batch, self.embedding_dim) pred_traj_fake_rel.append(rel_pos.view(batch, -1)) last_pos = curr_pos pred_traj_fake_rel = torch.stack(pred_traj_fake_rel, dim=0) # 预测的是相对坐标 return pred_traj_fake_rel, state_tuple[0]
在if self.pool_every_timestep: 如果不重新池化,那么decoder里输入的state_tuple(hh, ch)始终是根据前8个已知的轨迹和第8帧的和其他人的位置相对信息得到;如果要池化,那么就通过self.pool_net把上一次的hh和最新的预测坐标送入PoolHiddenNet得到新的pool_h。
这里有个疑问就是
for _ in range(self.seq_len):
TrajectoryGenerator(nn.Module) 接下来就是关于轨迹生成器的定义,__init__里面前面一大段就是参数的初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class TrajectoryGenerator(nn.Module): def __init__( self, obs_len, pred_len, embedding_dim=64, encoder_h_dim=64, decoder_h_dim=128, mlp_dim=1024, num_layers=1, noise_dim=(0, ), noise_type='gaussian', noise_mix_type='ped', pooling_type=None, pool_every_timestep=True, dropout=0.0, bottleneck_dim=1024, activation='relu', batch_norm=True, neighborhood_size=2.0, grid_size=8 ): super(TrajectoryGenerator, self).__init__() if pooling_type and pooling_type.lower() == 'none': pooling_type = None self.obs_len = obs_len self.pred_len = pred_len self.mlp_dim = mlp_dim self.encoder_h_dim = encoder_h_dim self.decoder_h_dim = decoder_h_dim self.embedding_dim = embedding_dim self.noise_dim = noise_dim self.num_layers = num_layers self.noise_type = noise_type self.noise_mix_type = noise_mix_type self.pooling_type = pooling_type self.noise_first_dim = 0 self.pool_every_timestep = pool_every_timestep self.bottleneck_dim = 1024
然后就是encoder和decode的一些参数初始化,在这里定义了pool_net函数,作用是根据输入参数调用PoolHiddenNet对LSTM得到的最后输出的隐藏层向量做池化操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 self.encoder = Encoder( embedding_dim=embedding_dim, h_dim=encoder_h_dim, mlp_dim=mlp_dim, num_layers=num_layers, dropout=dropout ) self.decoder = Decoder( pred_len, embedding_dim=embedding_dim, h_dim=decoder_h_dim, mlp_dim=mlp_dim, num_layers=num_layers, pool_every_timestep=pool_every_timestep, dropout=dropout, bottleneck_dim=bottleneck_dim, activation=activation, batch_norm=batch_norm, pooling_type=pooling_type, grid_size=grid_size, neighborhood_size=neighborhood_size ) if pooling_type == 'pool_net': self.pool_net = PoolHiddenNet( embedding_dim=self.embedding_dim, h_dim=encoder_h_dim, mlp_dim=mlp_dim, bottleneck_dim=bottleneck_dim, activation=activation, batch_norm=batch_norm )
再来看forward()函数的内容,前面作者的注释很详细,对于Dataloader传来的数据大小给出了很详细的说明
1 2 3 4 5 6 7 8 9 10 11 def forward(self, obs_traj, obs_traj_rel, seq_start_end, user_noise=None): """ Inputs: - obs_traj: Tensor of shape (obs_len, batch, 2) - obs_traj_rel: Tensor of shape (obs_len, batch, 2) - seq_start_end: A list of tuples which delimit sequences within batch. - user_noise: Generally used for inference when you want to see relation between different types of noise and outputs. Output: - pred_traj_rel: Tensor of shape (self.pred_len, batch, 2) """
然后就是对传入的数据依次处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 batch = obs_traj_rel.size(1) # Encode seq final_encoder_h = self.encoder(obs_traj_rel) # 对轨迹做encoder得到最后的隐藏状态 # Pool States if self.pooling_type: # 如果加入池化层 end_pos = obs_traj[-1, :, :] pool_h = self.pool_net(final_encoder_h, seq_start_end, end_pos) # Construct input hidden states for decoder mlp_decoder_context_input = torch.cat( [final_encoder_h.view(-1, self.encoder_h_dim), pool_h], dim=1) else: mlp_decoder_context_input = final_encoder_h.view( -1, self.encoder_h_dim)
在这里:
如果加入了池化层则将上一步encoder得到的最终隐藏层向量final_encoder_h等数据送入池化层,得到每个人的特征向量pool_h,并将final_encoder_h与pool_h进行拼接,得到mlp_decoder_context_input。
没有池化层,直接将上一步得到的final_encoder_h经过维度变换作为mlp_decoder_context_input
在加入噪声前,也需要对得到的数据进行维度处理,保证输入的维度和add_noise()定义的_input格式大小(_, decoder_h_dim(128) - noise_first_dim)一致。如果上面做了拼接,那么mlp_decoder_context_input中每一行的长度就是h_dim(64)+bottleneck_dim(1024)=1088维,但是add_noise()里定义的_input长度是decoder_h_dim - noise_first_dim,所以需要加一个MLP,如下:
1 2 3 4 5 6 7 8 9 10 11 12 # 增加全连接层 if self.mlp_decoder_needed(): mlp_decoder_context_dims = [ input_dim, mlp_dim, decoder_h_dim - self.noise_first_dim ] self.mlp_decoder_context = make_mlp( mlp_decoder_context_dims, activation=activation, batch_norm=batch_norm, dropout=dropout )
保证输入的长度decoder_h_dim - self.noise_first_dim,即在后面加上噪声后长度大小满足decoder_h的要求(decoder_h_dim)。
关于添加噪声的处理,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 def add_noise(self, _input, seq_start_end, user_noise=None): """ Inputs: - _input: Tensor of shape (_, decoder_h_dim - noise_first_dim) - seq_start_end: A list of tuples which delimit sequences within batch. - user_noise: Generally used for inference when you want to see relation between different types of noise and outputs. Outputs: - decoder_h: Tensor of shape (_, decoder_h_dim) """ if not self.noise_dim: return _input # 全局噪声还是非全局噪声 # 如果是全局噪声,则每个人的噪声都一样,否则每个人的噪声都不一样。 if self.noise_mix_type == 'global': noise_shape = (seq_start_end.size(0), ) + self.noise_dim else: noise_shape = (_input.size(0), ) + self.noise_dim if user_noise is not None: z_decoder = user_noise else: z_decoder = get_noise(noise_shape, self.noise_type) if self.noise_mix_type == 'global': _list = [] for idx, (start, end) in enumerate(seq_start_end): start = start.item() end = end.item() _vec = z_decoder[idx].view(1, -1) _to_cat = _vec.repeat(end - start, 1) _list.append(torch.cat([_input[start:end], _to_cat], dim=1)) decoder_h = torch.cat(_list, dim=0) return decoder_h decoder_h = torch.cat([_input, z_decoder], dim=1) return decoder_h
所以在这里,经过Pooling Module模块后,三个类型的长方形和所代表的数据便一一对应上了。
回到forward()这里,经过全连接层之后,将得到的noise_input与一个噪声z进行合并,得到decoder_h
1 2 3 4 5 6 7 8 9 decoder_h = self.add_noise( noise_input, seq_start_end, user_noise=user_noise) decoder_h = torch.unsqueeze(decoder_h, 0) # LSTM网络定义的num_layers=1,所以用unsqueeze加了一个维度? # decoder_c的初始化,这里我把.cuda()改成了.to(device) decoder_c = torch.zeros( self.num_layers, batch, self.decoder_h_dim ).to(device)
最后就是把轨迹数据丢到decoder中,得到后12帧的预测轨迹pred_traj_fake_rel,大小为(self.pred_len, batch, 2)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 state_tuple = (decoder_h, decoder_c) last_pos = obs_traj[-1] last_pos_rel = obs_traj_rel[-1] # Predict Trajectory decoder_out = self.decoder( last_pos, last_pos_rel, state_tuple, seq_start_end, ) pred_traj_fake_rel, final_decoder_h = decoder_out return pred_traj_fake_rel
接下来,就是最后一个类TrajectoryDiscriminator了,这个类比较简单。其主要就是对轨迹进行打分,以判断轨迹是真实的轨迹还是预测的轨迹。其主要是copy了一份上文encoder部分的网络,然后得到final_h,另外又搭建了一个全连接层,该全连接层输出网络生成的分数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 class TrajectoryDiscriminator(nn.Module): def __init__( self, obs_len, pred_len, embedding_dim=64, h_dim=64, mlp_dim=1024, num_layers=1, activation='relu', batch_norm=True, dropout=0.0, d_type='local' ): super(TrajectoryDiscriminator, self).__init__() self.obs_len = obs_len self.pred_len = pred_len self.seq_len = obs_len + pred_len self.mlp_dim = mlp_dim self.h_dim = h_dim self.d_type = d_type self.encoder = Encoder( embedding_dim=embedding_dim, h_dim=h_dim, mlp_dim=mlp_dim, num_layers=num_layers, dropout=dropout ) real_classifier_dims = [h_dim, mlp_dim, 1] self.real_classifier = make_mlp( real_classifier_dims, activation=activation, batch_norm=batch_norm, dropout=dropout ) if d_type == 'global': mlp_pool_dims = [h_dim + embedding_dim, mlp_dim, h_dim] self.pool_net = PoolHiddenNet( embedding_dim=embedding_dim, h_dim=h_dim, mlp_dim=mlp_pool_dims, bottleneck_dim=h_dim, activation=activation, batch_norm=batch_norm ) def forward(self, traj, traj_rel, seq_start_end=None): """ Inputs: - traj: Tensor of shape (obs_len + pred_len, batch, 2) - traj_rel: Tensor of shape (obs_len + pred_len, batch, 2) - seq_start_end: A list of tuples which delimit sequences within batch Output: - scores: Tensor of shape (batch,) with real/fake scores """ final_h = self.encoder(traj_rel) # Note: In case of 'global' option we are using start_pos as opposed to # end_pos. The intution being that hidden state has the whole # trajectory and relative postion at the start when combined with # trajectory information should help in discriminative behavior. if self.d_type == 'local': classifier_input = final_h.squeeze() else: classifier_input = self.pool_net( final_h.squeeze(), seq_start_end, traj[0] ) scores = self.real_classifier(classifier_input) return scores