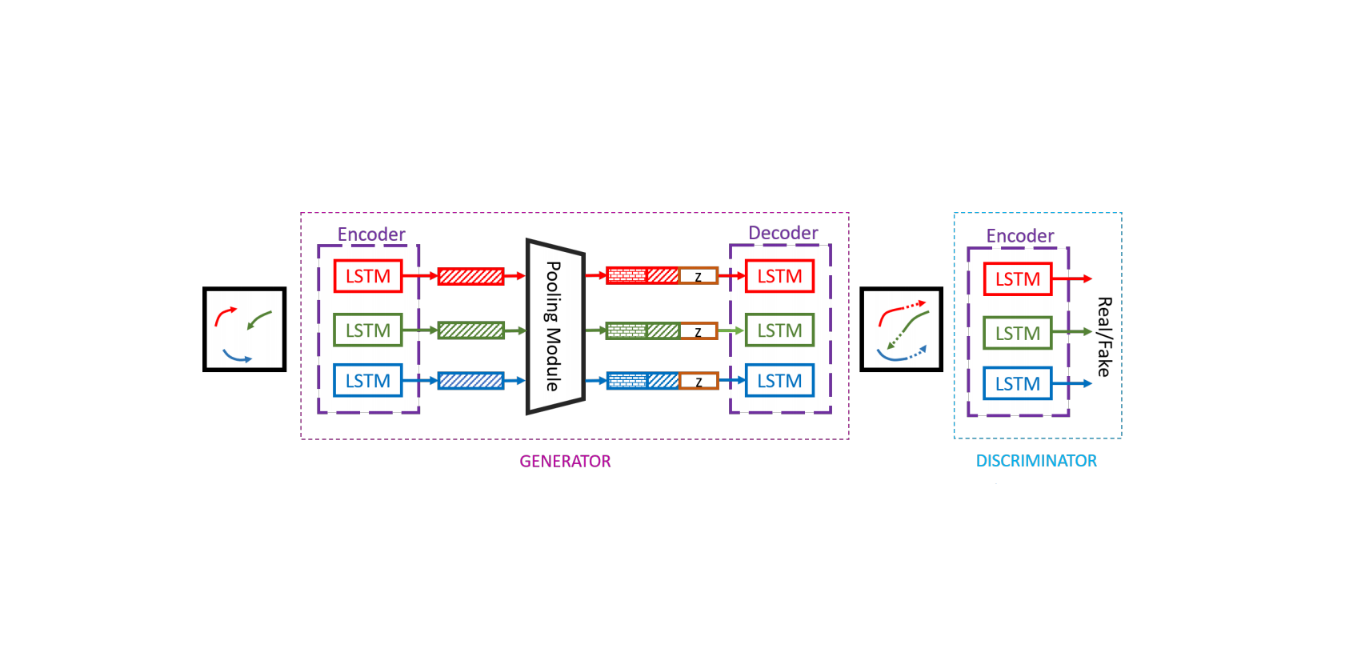
Social-GAN Open Source Code Analysis(1)
This blog is an open source code analysis of the paper by Fei-Fei Li et al
Social-GAN,Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks(CVPR,2018)
持续更新中…
近日在实验室复现18年李飞飞组的行人轨迹预测论文Social-GAN,Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks(CVPR,2018)。
作为轨迹预测领域的一开山之作,至今引用已超1000次,即使放到2022年其思想和代码也有很多值得借鉴的地方。
网上对于该文献及官方源码的解读颇多,为了巩固,也作此博文记录一番。
数据集准备
下载问题
解压
ETH和UCY数据集
数据集链接: https://data.vision.ee.ethz.ch/cvl/aess/
https://blog.csdn.net/T_C_Ko/article/details/121961696?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_antiscanv2&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_antiscanv2&utm_relevant_index=2
EWAP的数据集包括两个sequence:eth和hotel
UCY的数据集包括三个sequence:student、univ和zara,还有分zara01,zara02等
两个数据集视角为俯视视角的群体行人运动轨迹,目前在开源代码中使用eth数据集的方法往往是采用已经经过预处理脚本的文本文档(抽帧采样计算),文本文档中主要保存了行人ID,帧数,以及坐标位置。
数据集图片[]
模型加载 (loader.py)
Social GAN源码是基于pytorch框架,pytorch的数据加载到模型的操作顺序主要包括一下三步
- 创建一个Dataset对象
Dataset是一个代表着数据集的抽象类,所有关于数据集的类都可以定义成其子类,只需要重写部分函数即可。
①__init__:传入数据,或者直接在函数里加载数据
②__len__(self):返回这个数据集一共有多少个item
③__getitem__(self, index):返回第index条训练数据,并将其转换成tensor
而Social GAN中dataset的对象定义写在了trajectories.py中
1 | class TrajectoryDataset(Dataset): |
用dataset[0]可以调用了上面定义的def getitem()那个函数,传入的idx=0,也就是取第0个数据。
- 创建一个Dataloader对象
Dataloader本质是一个可迭代对象,将打包好数据集中一个batch size大小数据,每一步生成一个batch,依次送入网络中用于后面的训练。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def data_loader(args, path):
dset = TrajectoryDataset(
path,
obs_len=args.obs_len,
pred_len=args.pred_len,
skip=args.skip,
delim=args.delim)
loader = DataLoader(
dset, # TrajectoryDataset准备好的数据集
batch_size=args.batch_size, # 每个batch中有多少样本官方默认的是64个
shuffle=True, # 是否将数据打乱
num_workers=args.loader_num_workers, # 处理数据加载的进程数
collate_fn=seq_collate) # 将一个列表中的样本组成一个mini-batch的函数
return dset, loader
值得注意的是,在定义Dataloader对象中,dataloader按照batch进行取数据的时候, 是取出大小等同于batch size的index列表; 然后将列表列表中的index输入到dataset的getitem()函数中,取出该index对应的数据; 最后, 对每个index对应的数据进行堆叠, 就形成了一个batch的数据。
在相应的参数中,collate_fn参数作用是指定整理数据的函数,该函数将一个batch的数据重新打包成要需要的数据格式(加工处理、维度变换),以便送入网络进行训练,如果没有指定,那么在pytorch的源码中collate_fn默认了一个default_collate函数。
为了保证输入到LSTM网络的数据格式一致,所以作者在trajectories.py定义了seq_collate函数并赋给collate_fn。
传入seq_collate数据,是已经堆叠好的batch个数据,被弄成一个列表list的形式。
1 | batch = [dataset[0],dataset[1],...,dataset[N]] |
参考视频:https://mp.weixin.qq.com/s/Uc2LYM6tIOY8KyxB7aQrOw
https://www.jianshu.com/p/bb90bff9f6e5
https://blog.csdn.net/dong_liuqi/article/details/114521240
- 循环dataloader对象,将data,label拿到模型中去训练
数据处理部分
trajectories.py
读取文件 read_file()
原始的数据集共有4列,分为为frame id,ped id,x,y
打开_path路径下的文件,将数据每一行按delim分割并转换成flost
然后依次加入data list中
最终返回一个array数组
open()as :https://blog.csdn.net/NeverLate_gogogo/article/details/85292663
1 | def read_file(_path, delim='\t'): |
https://blog.csdn.net/Waitfou/article/details/76342619
https://blog.csdn.net/haowen11/article/details/107344007
定义轨迹数据集类 TrajectoryDataset(Dataset)
__init__传入参数参数及其默认如下
1 | data_dir, 数据集合路径 |
TrajectoryDataset类的一些参数初始化
1 | super(TrajectoryDataset, self).__init__() |
读取数据集路径
1 | all_files = os.listdir(self.data_dir) |
接下来定义的是一系列list用于保存进一步处理得到的数据
在这之前,需要明确的是Social GAN代码中将20帧(frame)的数据定义成了一个序列(sequence),数据集中帧id 从0开始:0,10,20…
从第0帧开始,依次滑动抽取20帧作为一个序列,即
序列1: [帧00, 帧10, 帧20, …, 帧190]
序列2: [帧10, 帧20, 帧30, …, 帧200]
序列3: [帧20, 帧30, 帧40, …, 帧210]
1 | num_peds_in_seq = [] # 一个序列里面出现的所有人id列表 |
第一循环表示依次读取出path路径下.txt轨迹文件的内容
1 | data = read_file(path, delim) |
frame_data数据形式如下
以20帧为一个窗口从第0帧开始滑动,得到数据集中sequences的数目(int)
1 | num_sequences = int( |
随后进入第二个循环,在每个循环中对frame_data一个sequence的数据在axis=0方向上做concatenate,得到curr_seq_data数组
1 | for idx in range(0, num_sequences * self.skip + 1, skip): |
peds_in_curr_seq是一个np.ndarray,表示在第idx序列中出现的所有行人的id数组,例如
idx = 0, peds_in_curr_seq = [ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16.]
idx = 4, peds_in_curr_seq = [ 3. 4. 5. 6. 7. 8. 11. 12. 13. 14. 15. 16. 17. 18.]
第三个循环里面,对peds_in_curr_seq按出现的行人id数进行循环,通过
1 | curr_seq_data[:, 1] == ped_id |
抽取第ped_id个行人的坐标
通过取[0, 0]和[-1, 0]可以得到该行人第一次出现的帧id和最后一次出现的帧id,作为pad_front和pad_end,二者相减即可得到对应的轨迹长度(出现在画面中的帧数)
1 | num_peds_considered = 0 # 一个sequence里完整出现20帧的人的个数 |
此外,在此循环中,还进行了一个判断,如果这个人轨迹序列长度小于20,那么就跳过循环(计算该序列中下一个人),并且在后面的轨迹预测中不考虑这个人的数据信息。
1 | # 找到一个序列中完整出现20个轨迹点的人 |
这里首先对curr_ped_seq中x,y坐标做了一个转置
随后计算行人在相邻帧下的相对坐标rel_curr_ped_seq
在一个idx循环中,最后主要得到
curr_seq,curr_seq_rel,num_peds_considered,_non_linear_ped,curr_loss_mask
后面两个参数没有仔细研究
curr_seq: 当前序列中满足轨迹=20的行人的坐标数组
curr_seq_rel: 当前序列中满足轨迹=20的行人的相对坐标数组
num_peds_considered: 当前序列中满足轨迹=20的人数
由前面的定义可知
1 | curr_seq_rel = np.zeros((len(peds_in_curr_seq), 2, self.seq_len)) |
curr_seq、curr_seq_rel数组的格式大小(该序列出现过的总人数, 坐标维度(2), 序列长度(20))
所以curr_seq格式如下:
进行到此处后,对于第idx个sequence里的轨迹,如果有效的轨迹人数>min_ped,则将对应的curr_seq(非零的坐标点)等参数加入到seq_list.append等之中
1 | # 如果一个序列中,出现20次的人数>最小人数 |
在这有一点疑问:
比如在idx = 3这个squence中,有效的轨迹长度是三条,但是在
1 | for _, ped_id in enumerate(peds_in_curr_seq): |
循环下,进行到num_peds_considered = 2时,就将curr_seq等append进seq_list之中,此时curr_seq没有保存第三个有效轨迹序列的坐标点。
然后同样是这个squence,num_peds_considered = 3,第三条轨迹被保存到curr_seq同时append进seq_list。
不太明白的就是,由于循环的原因,在相同squence下会多次保存轨迹信息进入到seq_list中,后一次会比前一次多一条信息。这样做的目的是为什么呢?
此时seq_list里面包含了数据集中所有sequence轨迹数据,再对对seq_list做concatenate
1 | self.num_seq = len(seq_list) |
得到如下
最后对完整的轨迹信息截取,并将numpy数组转化成Tensor
1 | self.obs_traj = torch.from_numpy( |
self.seq_start_end是一个元组列表,其长度(len(seq_start_end))表示一共有多少满足条件的sequcence,关于它的作用引用一下其他博主的解释
假设在所给数据集中一共有5个序列满足完整出现的人数大于min_ped,且这5个序列分别有2,3,2,4,3个人完整出现,那么self.seq_start_end的长度为5,self.seq_start_end等于[(0,2),(2,5),(5,7),(7,11),(11,14)],也就是说num_ped=14,self.seq_start_end的主要作用是为了以后一个一个序列的分析的方便,即由要分析的序列,即可根据它的值得到对应在这个序列中有哪几个人以及这几个人的所有相关数据。
就是说seq_start_end中的每个元组(start, end)都和一个sequence相对应,作用就是方便从obs_traj_rel等抽取一个sequence中的所有轨迹。具体实现可以见__getitem__函数。
由于TrajectoryDataset继承至Dataset类,所以其需要重写__getitem__和__len__函数
具体如下:
1 | # 返回处理后的数据的长度 |
__len__函数的作用就是得到处理后的数据的长度,在本例中,就是所有满足条件的序列的长度。
__getitem__函数的作用就是根据索引index返回__init__函数执行后的数据,在本例中就是返回一个数组,它包含一个sequence中轨迹等信息。
如果在类中定义了__getitem__()方法,那么他的实例对象(假设为P)就可以这样P[key]取值。当实例对象做P[key]运算时,就会调用类中的__getitem__()方法。
虽然说seq_list包含了数据集中所有轨迹的信息(按sequence排列),但是__getitem__()还是按照index,截取一个sequence数据合成Tenser作为out返回。
1 | # 返回__init__函数处理后一个序列的数据,通过getitem传给DataLoader |
主要的TrajectoryDataset类讲完后,还有其他函数
1 | # 拟合判断是否是线性 |
poly_fit()在这里不做赘述,只需要知道如果轨迹非线性return 1.0,线性则return 0.0即可。
Batch样本的处理 seq_collate(data)
前面讲了在Dataloader按照Batch进行取数据时,会按照index取出Batch size为一个data列表,collate_fn函数会对样本进行整理重新打包成要需要的数据格式,最后将这个Batch送入网络进行训练。
pytorch的源码中collate_fn默认了一个default_collate函数,但是在这里,由于每个sequence中有效轨迹的数目不一致,所以需要整理成统一格式大小,因此这里重写了collate_fn函数。
1 | def seq_collate(data): |
zip(*data)返回的是元组数据,obs_seq_list,pred_seq_list…也是batch_size个数据对应obs_traj,pred_traj…组成的元组。
通过len得到所有sequence里轨迹长度组成的列表_len,大小为batch_size,例如
_len = [2, 3, 2, 4, 3,….]
相应地,此时
cum_start_idx = [0, 2, 5, 7, 11, 14…]
seq_start_end = [[0, 2], [2, 5], [5, 7], [7, 11]…]
剩下的主要是根据LSTM的输入方式,做维度变换[N,2,seq_len]→[seq_len,N,2]
1 | # Data format: batch, input_size, seq_len |
例如